
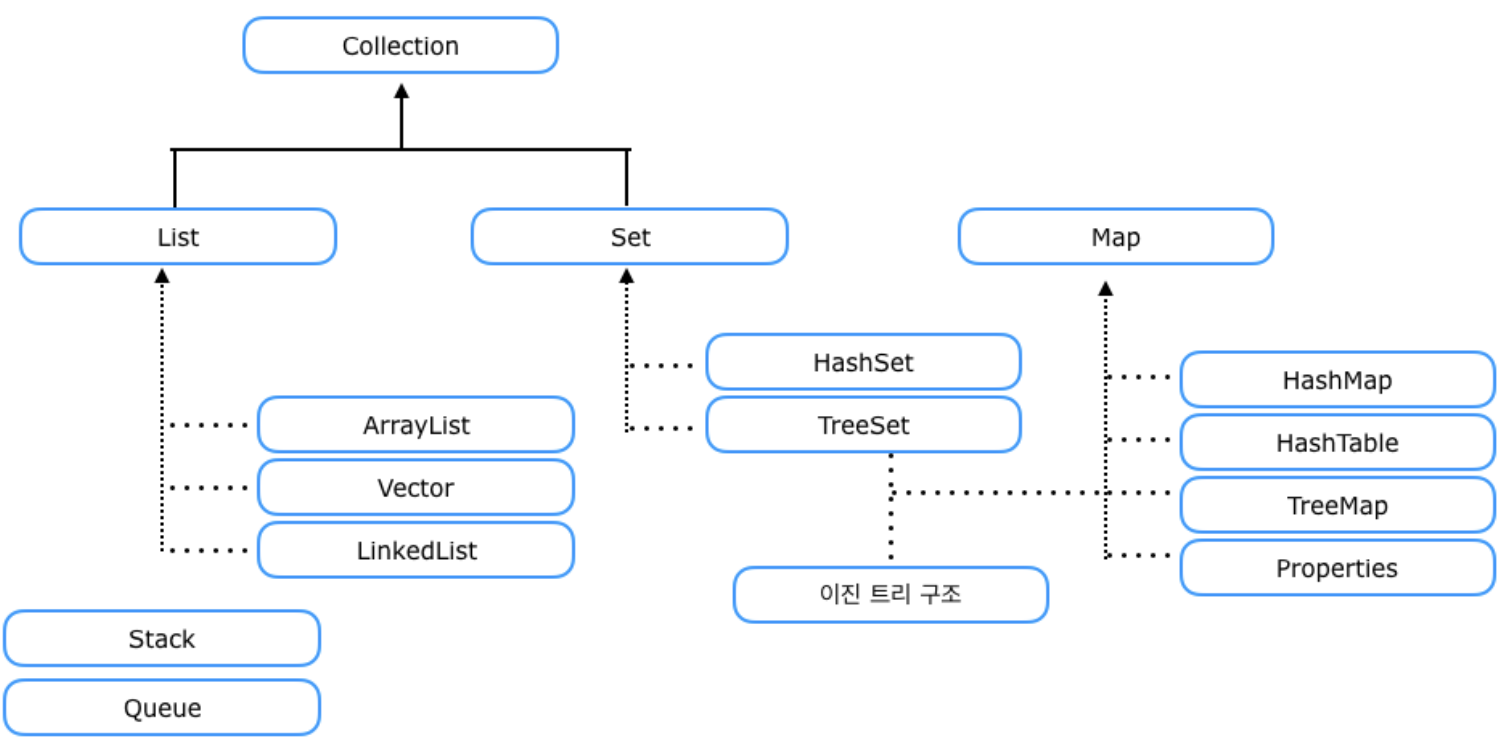
1. Map ( HashMap, Hashtable, LinkedHashMap, TreeMap )
Map은 Key와 Value라는 것을 한 쌍으로 갖는 자료형이다. Map은 사물함을 연상할 수 있다.
사물함은 번호가 있고 그 안에 내용물이 있는것처럼 사물함번호가 Key값이 되고 그 안에 Value가 저장된다.
만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
Map :순서 X , key 중복 X value 중복 O 검색 !
특별한 사유가 없다면 검색 성능이 좋은 HashMap을 사용순서를 보장하고 싶다면 LinkedHashMap을 사용키값을 일정하게 정렬 하고자한다면 TreeMap을 사용
맵의 특징 으론
- 키(key)와 값(value)의 쌍으로 이루어져 있다.
- 맵(Map)은 순서가 없다.
- 키(key)는 중복 X. (키(key)가 중복이 된다면 마지막 키(key)로 대체된다.)
- 값(value)은 중복 O
- 키(key)는 인덱스(index)로 사용
- 키(key)는 set에 저장된다.
- 검색을 하는 목적으로 많이 사용된다.
- 맵(Map)은 순서가 없기 때문에 중간 삽입이 없다.
Map<자료형, 자료형> 맵 명 = new HashMap(or Hashtable)<자료형, 자료형(생략 가능)>(); Map 인터페이스는 자료형을 두개를 선언해 주어야 한다.
(key , value 가 한쌍이기 때문에...)
Tip :
Vector나 Hashtable과 같은 기존의 컬렉션 클래스들은 호환을 위해, 설계를 변경해서 남겨두었지만
가능하면 사용하지 않는 것이 좋다. ( ArrayList 와 HashMap을 사용)
쓰레드 세이프한 해시테이블 ?? (읽고 싶으신 분들만...)
해시테이블 함수는 synchronized(동기화)가 걸려 있기 때문에 멀티 스레드 환경에서 데이터 조작에 대한 일관성이 보장된다.
'Collections.synchronizedMap'처럼 synchronized를 래핑하는 함수를 활용하면 HashMap도 충분히 스레드 세이프 하게 동작 시킬수 있다.
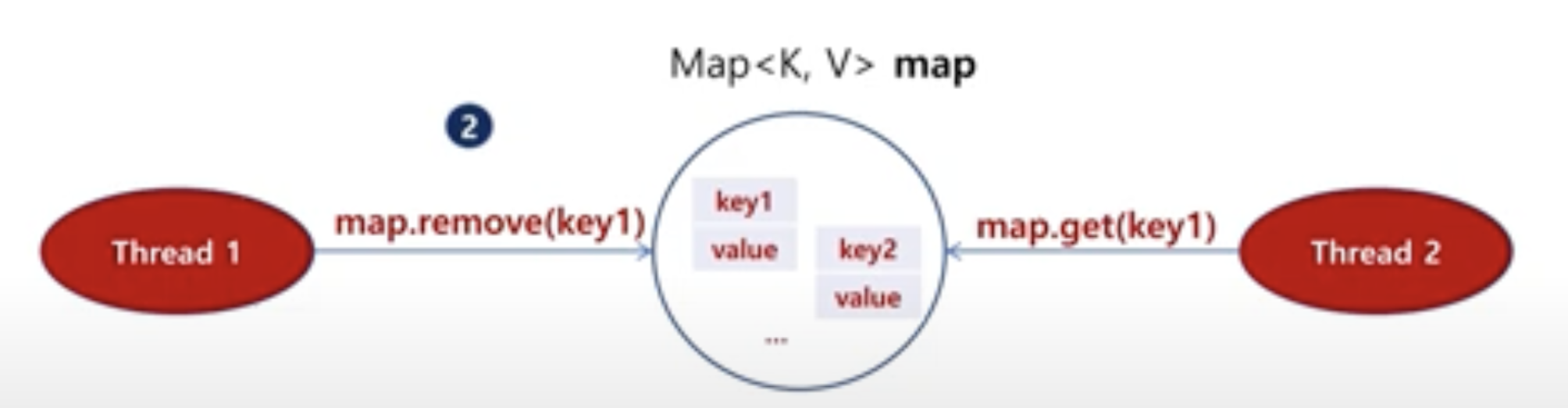
스레드 1에서 key1을 지우고자 할때, 동시에 스레드 2에서 key1의 값을 받아오는 경우.
HashTable의 경우 key1 을 삭제 할때 key1 이 다른 동작을 할 수 없게 lock을 걸어준다. (동기화 synchronized) 이다.
멀티스레드 환경에선 해쉬맵 객체를 공유하면 안된다.
< 멀티스레드엔 Hashtable 만 사용해야하나 ? ㄴㄴ synchronizedMap / synchronizedSet 이거사용하면 됌 >
원래 데이터의 값(Key) -> Hash Function -> Hash Function의 결과 = Hash Code
-> Hash Code를 배열의 Index 로 사용 -> 해당하는 Index에 data 넣기
하지만 여기서 문제가 있다. Hash Function 을 통해 Hash 한 결과가 같은(중복) 경우이다.
해쉬값이 중복이 되면 먼저 들어온 데이터가 지워지기 때문에 이러한 문제를 해결하기 위한 LinkedHashMap 을 사용한다.
HashMap 과 LinkedHashMap 의 차이점
HashMap 순서 x
LinkedHashMap 순서 o FIFO (First In First Out) 파이프라인
HashMap
- 내부적으로 Entry<K,V>[] Entry 의 array 로 되어 있으며, 해당 array 에 index 는 내부 해쉬 함수를 통해 계산됩니다.
- HashMap은 Map 인터페이스의 한 종류로 Key와 Value 한 쌍을 데이터로 가지고 있으며
Key를 통해 Value에 접근할 수 있습니다. - HashMap은 그 안에 들어있는 데이터를 Set 구조(key,value)로 저장하기 때문에
Set의 원칙대로 중복된 데이터를 허락하지 않으면서 순서가 없습니다. - hashing을 사용하기 때문에 많은양의 데이터를 검색하는데 뛰어난 성능을 가지고 있습니다.
LinkedHashMap ( 순서가 있는 HashMap )
- LinkedHashMap은 순서를 유지하기 위해 이중 연결 리스트 Doubly Linked List를 사용합니다.
- FIFO (First In First Out) 구조로 데이터를 저장합니다.
- HashMap의 모든 기능을 그대로 사용할 수 있습니다.
- 순서를 유지하기 때문에 메모리 사용량이 HashMap보다 높습니다.
TreeMap
- key 값에 따라서 자동으로 Sort가 되는 방식입니다.
- 동기화(synchronized) 처리가 되어 있어 Thread-safe 합니다.
- HashMap과는 다르게 Key 값으로 null을 허용하지 않습니다.
- 내부적으로 RedBlack Tree로 저장되며, 키값에 대한 Compartor 구현으로 정렬 순서를 바꿀수 있습니다.
'개-발 > Java + Spring + Kotlin' 카테고리의 다른 글
| [Spring] 연관관계 맵핑 (0) | 2022.12.26 |
|---|---|
| [JAVA] Stream / 중간연산 (0) | 2022.12.12 |
| [JAVA] 컬렉션 프레임워크 ( List, Set ) (0) | 2022.12.04 |
| [JAVA] 객체지향설계 SOLID 원칙 (0) | 2022.12.04 |
| [JAVA] Lambda 람다표현식 (0) | 2022.12.01 |
1. Map ( HashMap, Hashtable, LinkedHashMap, TreeMap )
Map은 Key와 Value라는 것을 한 쌍으로 갖는 자료형이다. Map은 사물함을 연상할 수 있다.
사물함은 번호가 있고 그 안에 내용물이 있는것처럼 사물함번호가 Key값이 되고 그 안에 Value가 저장된다.
만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
Map :순서 X , key 중복 X value 중복 O 검색 !
특별한 사유가 없다면 검색 성능이 좋은 HashMap을 사용순서를 보장하고 싶다면 LinkedHashMap을 사용키값을 일정하게 정렬 하고자한다면 TreeMap을 사용
맵의 특징 으론
- 키(key)와 값(value)의 쌍으로 이루어져 있다.
- 맵(Map)은 순서가 없다.
- 키(key)는 중복 X. (키(key)가 중복이 된다면 마지막 키(key)로 대체된다.)
- 값(value)은 중복 O
- 키(key)는 인덱스(index)로 사용
- 키(key)는 set에 저장된다.
- 검색을 하는 목적으로 많이 사용된다.
- 맵(Map)은 순서가 없기 때문에 중간 삽입이 없다.
Map<자료형, 자료형> 맵 명 = new HashMap(or Hashtable)<자료형, 자료형(생략 가능)>(); Map 인터페이스는 자료형을 두개를 선언해 주어야 한다.
(key , value 가 한쌍이기 때문에...)
Tip :
Vector나 Hashtable과 같은 기존의 컬렉션 클래스들은 호환을 위해, 설계를 변경해서 남겨두었지만
가능하면 사용하지 않는 것이 좋다. ( ArrayList 와 HashMap을 사용)
쓰레드 세이프한 해시테이블 ?? (읽고 싶으신 분들만...)
해시테이블 함수는 synchronized(동기화)가 걸려 있기 때문에 멀티 스레드 환경에서 데이터 조작에 대한 일관성이 보장된다.
'Collections.synchronizedMap'처럼 synchronized를 래핑하는 함수를 활용하면 HashMap도 충분히 스레드 세이프 하게 동작 시킬수 있다.
스레드 1에서 key1을 지우고자 할때, 동시에 스레드 2에서 key1의 값을 받아오는 경우.
HashTable의 경우 key1 을 삭제 할때 key1 이 다른 동작을 할 수 없게 lock을 걸어준다. (동기화 synchronized) 이다.
멀티스레드 환경에선 해쉬맵 객체를 공유하면 안된다.
< 멀티스레드엔 Hashtable 만 사용해야하나 ? ㄴㄴ synchronizedMap / synchronizedSet 이거사용하면 됌 >
원래 데이터의 값(Key) -> Hash Function -> Hash Function의 결과 = Hash Code
-> Hash Code를 배열의 Index 로 사용 -> 해당하는 Index에 data 넣기
하지만 여기서 문제가 있다. Hash Function 을 통해 Hash 한 결과가 같은(중복) 경우이다.
해쉬값이 중복이 되면 먼저 들어온 데이터가 지워지기 때문에 이러한 문제를 해결하기 위한 LinkedHashMap 을 사용한다.
HashMap 과 LinkedHashMap 의 차이점
HashMap 순서 x
LinkedHashMap 순서 o FIFO (First In First Out) 파이프라인
HashMap
- 내부적으로 Entry<K,V>[] Entry 의 array 로 되어 있으며, 해당 array 에 index 는 내부 해쉬 함수를 통해 계산됩니다.
- HashMap은 Map 인터페이스의 한 종류로 Key와 Value 한 쌍을 데이터로 가지고 있으며
Key를 통해 Value에 접근할 수 있습니다. - HashMap은 그 안에 들어있는 데이터를 Set 구조(key,value)로 저장하기 때문에
Set의 원칙대로 중복된 데이터를 허락하지 않으면서 순서가 없습니다. - hashing을 사용하기 때문에 많은양의 데이터를 검색하는데 뛰어난 성능을 가지고 있습니다.
LinkedHashMap ( 순서가 있는 HashMap )
- LinkedHashMap은 순서를 유지하기 위해 이중 연결 리스트 Doubly Linked List를 사용합니다.
- FIFO (First In First Out) 구조로 데이터를 저장합니다.
- HashMap의 모든 기능을 그대로 사용할 수 있습니다.
- 순서를 유지하기 때문에 메모리 사용량이 HashMap보다 높습니다.
TreeMap
- key 값에 따라서 자동으로 Sort가 되는 방식입니다.
- 동기화(synchronized) 처리가 되어 있어 Thread-safe 합니다.
- HashMap과는 다르게 Key 값으로 null을 허용하지 않습니다.
- 내부적으로 RedBlack Tree로 저장되며, 키값에 대한 Compartor 구현으로 정렬 순서를 바꿀수 있습니다.
'개-발 > Java + Spring + Kotlin' 카테고리의 다른 글
| [Spring] 연관관계 맵핑 (0) | 2022.12.26 |
|---|---|
| [JAVA] Stream / 중간연산 (0) | 2022.12.12 |
| [JAVA] 컬렉션 프레임워크 ( List, Set ) (0) | 2022.12.04 |
| [JAVA] 객체지향설계 SOLID 원칙 (0) | 2022.12.04 |
| [JAVA] Lambda 람다표현식 (0) | 2022.12.01 |