
파일의 입출력을 위해서는 inputStream을 이용하여 Stream을 생성하고 데이터를 읽어온다.
지금까지 파일을 보내고 받아오는 과정에서
단어의 정의나 데이터가 전송되는 과정을 명확히 파악하지 못하고 있었다.
데이터가 전송되는 과정
import java.io.FileInputStream;
public class Main {
public static void main(String[] args) {
try{
FileInputStream fileInputStream = new FileInputStream("practice.txt");
int i =0;
while ((i = fileInputStream.read()) != -1) {
System.out.print((char) i);
}
fileInputStream.close();
}catch (Exception e) {
System.out.println(e);
}
}
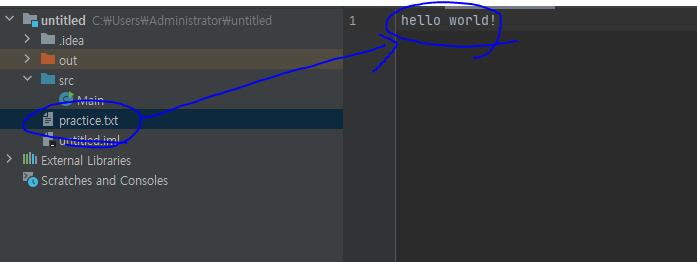
}practice.txt를 이동 시키는 과정은
practice.txt를 전송시킬 InputStream을 생성한다.
이후 while문을 사용해서 practice.txt 를 byte 단위( 위 코드에서 -> i )로 전송한다
여기서 문제는 바이트 단위로 전송하기 때문에 byte 하나하나 보내기 때문에 I/O 오버헤드가 발생된다.오버헤드 = 스위치를 계속 올렸다 내렸다 한다고 생각하면 편하다
이것을 극복하기 위해 byte를 묶어서 전송시키는 방법이 있다.
한 묶음마다 I/O가 발생되니 그래도 위 방법보다 저렴하다.
그 방법이 Buffer 이다
Buffer
버퍼링의 버퍼 이다.
public class BufferedReadExample {
public static void main(String[] args) {
// 파일 경로 설정
String filePath = "path/to/your/file.txt";
// 버퍼 크기 설정
int bufferSize = 1024; // 1KB 버퍼
// 파일에서 데이터를 읽어오기
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(filePath), bufferSize)) {
byte[] buffer = new byte[bufferSize];
int bytesRead;
// 데이터 읽기
while ((bytesRead = bufferedInputStream.read(buffer)) != -1) {
// 읽어온 데이터를 처리 (여기서는 콘솔에 출력)
System.out.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}인터넷에서 영상을 보면 회색으로 먼저 로딩된 미디어를 볼 수 있다 그것이 버퍼단위로 읽어 온 데이터 이다.
new BufferedInputStream(new FileInputStream(filePath), bufferSize))버퍼 사이즈만큼 파일인풋을 잘라놓은 BufferedInputStream 을 만들어 놓은 후
bufferedInputStream.read(buffer)BufferedInputStream 에서 데이터를 읽어와 메모리에 올린다
설정해둔 버퍼사이즈만큼 읽어서 I/O 오버헤드를 최소화 해줄 수 잇다.
실제 예제
이 예제는 실제 apach commons-email 라이브러리의 소스코드이다.
//apache commons-email 수정 전
protected DataSource createDataSource(final Multipart parent, final MimePart part)
throws MessagingException, IOException
{
final DataHandler dataHandler = part.getDataHandler();
final DataSource dataSource = dataHandler.getDataSource();
final String contentType = getBaseMimeType(dataSource.getContentType());
byte[] content;
try (InputStream inputStream = dataSource.getInputStream())
{
content = this.getContent(inputStream);
}
final ByteArrayDataSource result = new ByteArrayDataSource(content, contentType);
final String dataSourceName = getDataSourceName(part, dataSource);
result.setName(dataSourceName);
return result;
}위 코드를 보면 데이터를 content 변수에 할당해서 ByteArrayDataSource 객체를 만들어 준 후 DataSource 객체를 반환해 준다.
content = this.getContent(inputStream);이렇게 되면 데이터가 content 변수에 할당하는 과정에서 데이터가 메모리에 올라가,
데이터 양에 따라 서버의 OOM( out of memory ) 가 발생 된다.
수정된 코드
protected DataSource createDataSource(final Multipart parent, final MimePart part)
throws MessagingException, IOException
{
final DataHandler dataHandler = part.getDataHandler();
final DataSource dataSource = dataHandler.getDataSource();
final String contentType = getBaseMimeType(dataSource.getContentType());
final String dataSourceName = getDataSourceName(part, dataSource);
return new AttachmentDataSource(dataSource.getInputStream(), contentType, dataSourceName);
}수정 된 코드를 보면 inputStream을 AttachmentDataSource로 Wrapping하고 반환해서 데이터를 실시간으로 전송시킨다.
단점이라고 하면 중간에 네트워크가 끊기거나 장애가 발생되면 데이터가 유실 될 수 있다.
하지만 이것으로 더 많은 것들이 개선이 된다.
개선된 결과를 보자
trade off
TPS 변화
아래는 그 결과이다. 첨부파일 데이터가 필요 없는 경우 해당 데이터를 byte[]에 할당할 필요가 없어져서 처리량이 올라갔다.

메모리 사용량
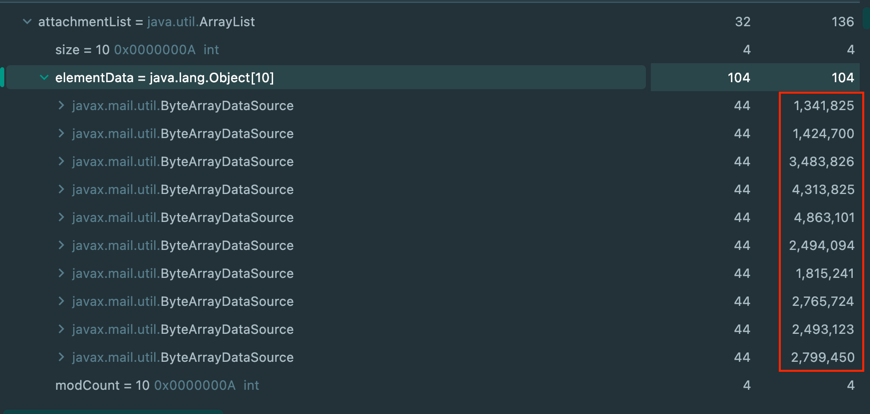
기존에는 전체 첨부파일을 byte[]에 옮겨담고 있었다.
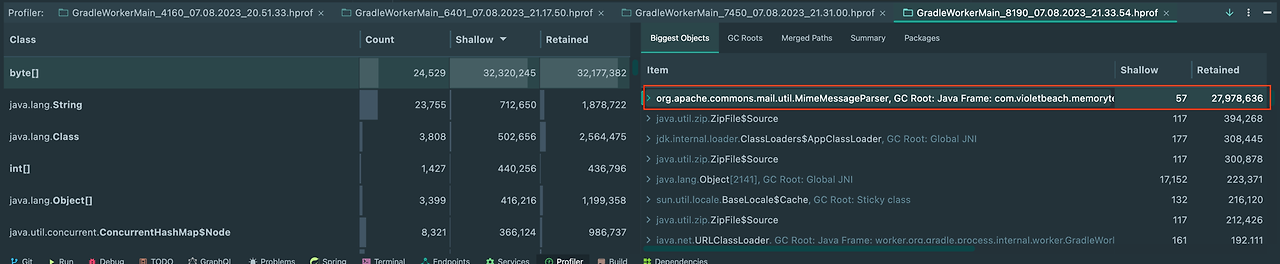
코드를 수정한 후에는 아래와 같이 메모리를 사용하지 않게 되었다.
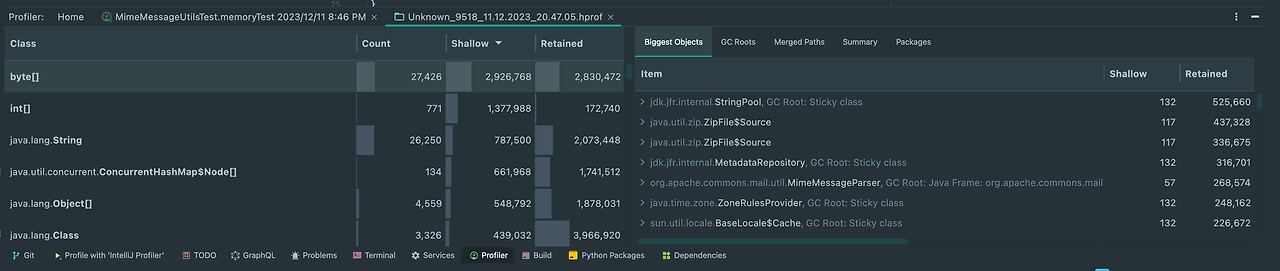
결과
아래는 총 개선 결과이다.
- TPS: 1.7 -> 21.7
- 메모리 사용량: 약 30MB -> 거의 X
- 평균 소요 시간: 14.82s -> 3.003s
- 90% 요청 소요 시간: 21.247s -> 5.523s
'일-상 > 오류노트' 카테고리의 다른 글
| [오류노트] 실패한 요청을 재시도 하지 말자 DeadLetter queue (0) | 2024.09.05 |
|---|---|
| [Mac] 맥북 오른쪽 커맨드키(command⌘) -> 한영키로 바꾸기 (5) | 2024.08.24 |
| [IntelliJ] 윈도우에서 맥os 키 매핑 (0) | 2024.08.22 |
| [오류노트] Mixed Content: The page at ~ (0) | 2024.08.20 |
| [오류노트] ERROR: relation "batch_job_instance" does not exist (0) | 2024.07.24 |
파일의 입출력을 위해서는 inputStream을 이용하여 Stream을 생성하고 데이터를 읽어온다.
지금까지 파일을 보내고 받아오는 과정에서
단어의 정의나 데이터가 전송되는 과정을 명확히 파악하지 못하고 있었다.
데이터가 전송되는 과정
import java.io.FileInputStream;
public class Main {
public static void main(String[] args) {
try{
FileInputStream fileInputStream = new FileInputStream("practice.txt");
int i =0;
while ((i = fileInputStream.read()) != -1) {
System.out.print((char) i);
}
fileInputStream.close();
}catch (Exception e) {
System.out.println(e);
}
}
}practice.txt를 이동 시키는 과정은
practice.txt를 전송시킬 InputStream을 생성한다.
이후 while문을 사용해서 practice.txt 를 byte 단위( 위 코드에서 -> i )로 전송한다
여기서 문제는 바이트 단위로 전송하기 때문에 byte 하나하나 보내기 때문에 I/O 오버헤드가 발생된다.오버헤드 = 스위치를 계속 올렸다 내렸다 한다고 생각하면 편하다
이것을 극복하기 위해 byte를 묶어서 전송시키는 방법이 있다.
한 묶음마다 I/O가 발생되니 그래도 위 방법보다 저렴하다.
그 방법이 Buffer 이다
Buffer
버퍼링의 버퍼 이다.
public class BufferedReadExample {
public static void main(String[] args) {
// 파일 경로 설정
String filePath = "path/to/your/file.txt";
// 버퍼 크기 설정
int bufferSize = 1024; // 1KB 버퍼
// 파일에서 데이터를 읽어오기
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(filePath), bufferSize)) {
byte[] buffer = new byte[bufferSize];
int bytesRead;
// 데이터 읽기
while ((bytesRead = bufferedInputStream.read(buffer)) != -1) {
// 읽어온 데이터를 처리 (여기서는 콘솔에 출력)
System.out.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}인터넷에서 영상을 보면 회색으로 먼저 로딩된 미디어를 볼 수 있다 그것이 버퍼단위로 읽어 온 데이터 이다.
new BufferedInputStream(new FileInputStream(filePath), bufferSize))버퍼 사이즈만큼 파일인풋을 잘라놓은 BufferedInputStream 을 만들어 놓은 후
bufferedInputStream.read(buffer)BufferedInputStream 에서 데이터를 읽어와 메모리에 올린다
설정해둔 버퍼사이즈만큼 읽어서 I/O 오버헤드를 최소화 해줄 수 잇다.
실제 예제
이 예제는 실제 apach commons-email 라이브러리의 소스코드이다.
//apache commons-email 수정 전
protected DataSource createDataSource(final Multipart parent, final MimePart part)
throws MessagingException, IOException
{
final DataHandler dataHandler = part.getDataHandler();
final DataSource dataSource = dataHandler.getDataSource();
final String contentType = getBaseMimeType(dataSource.getContentType());
byte[] content;
try (InputStream inputStream = dataSource.getInputStream())
{
content = this.getContent(inputStream);
}
final ByteArrayDataSource result = new ByteArrayDataSource(content, contentType);
final String dataSourceName = getDataSourceName(part, dataSource);
result.setName(dataSourceName);
return result;
}위 코드를 보면 데이터를 content 변수에 할당해서 ByteArrayDataSource 객체를 만들어 준 후 DataSource 객체를 반환해 준다.
content = this.getContent(inputStream);이렇게 되면 데이터가 content 변수에 할당하는 과정에서 데이터가 메모리에 올라가,
데이터 양에 따라 서버의 OOM( out of memory ) 가 발생 된다.
수정된 코드
protected DataSource createDataSource(final Multipart parent, final MimePart part)
throws MessagingException, IOException
{
final DataHandler dataHandler = part.getDataHandler();
final DataSource dataSource = dataHandler.getDataSource();
final String contentType = getBaseMimeType(dataSource.getContentType());
final String dataSourceName = getDataSourceName(part, dataSource);
return new AttachmentDataSource(dataSource.getInputStream(), contentType, dataSourceName);
}수정 된 코드를 보면 inputStream을 AttachmentDataSource로 Wrapping하고 반환해서 데이터를 실시간으로 전송시킨다.
단점이라고 하면 중간에 네트워크가 끊기거나 장애가 발생되면 데이터가 유실 될 수 있다.
하지만 이것으로 더 많은 것들이 개선이 된다.
개선된 결과를 보자
trade off
TPS 변화
아래는 그 결과이다. 첨부파일 데이터가 필요 없는 경우 해당 데이터를 byte[]에 할당할 필요가 없어져서 처리량이 올라갔다.
메모리 사용량
기존에는 전체 첨부파일을 byte[]에 옮겨담고 있었다.
코드를 수정한 후에는 아래와 같이 메모리를 사용하지 않게 되었다.
결과
아래는 총 개선 결과이다.
- TPS: 1.7 -> 21.7
- 메모리 사용량: 약 30MB -> 거의 X
- 평균 소요 시간: 14.82s -> 3.003s
- 90% 요청 소요 시간: 21.247s -> 5.523s
'일-상 > 오류노트' 카테고리의 다른 글
| [오류노트] 실패한 요청을 재시도 하지 말자 DeadLetter queue (0) | 2024.09.05 |
|---|---|
| [Mac] 맥북 오른쪽 커맨드키(command⌘) -> 한영키로 바꾸기 (5) | 2024.08.24 |
| [IntelliJ] 윈도우에서 맥os 키 매핑 (0) | 2024.08.22 |
| [오류노트] Mixed Content: The page at ~ (0) | 2024.08.20 |
| [오류노트] ERROR: relation "batch_job_instance" does not exist (0) | 2024.07.24 |